元智大學資管系第28屆專業實習
專題內容

工作環境介紹
我們三個人(洪英榤、詹秉樺、唐嘉宏)是在一館七樓 R1712 大數據中心工作,而教授在五樓也有分配 R1509B 的實驗室給其他的專題生,但主要工作地點還是在大數據中心,大數據中心相當於一個小型企業,有會議室、數個半開放式辦公桌、兩間辦公室以及小型的開放式茶水間,工作環境相當舒適、整潔,辦公室內的每個人都會定時打掃自己負責的區域。
工作環境介紹
室內因有空調系統所以通風良好,半開放式的辦公區域不只有一定程度的隱私保障,茶水間提供微波爐、電鍋、電磁爐等,電氣設備以供辦公室內的人可以準備午餐,也有水槽可以清洗餐具、保持清潔,茶水間與兩間辦公室皆有對外窗,若當天天氣晴朗則在辦公室內工作時甚至可以不用開燈,不只節省能源,也讓工作環境更為自然、令人心曠神怡,中午休息時間可以在茶水間靠著流理台望著窗外享受片刻的寧靜、忙裡偷閒。辦公室內的職員基本上不只一位中心助理還有一位工程師,然後工程師也非常熱心的幫助我們熟悉機房的相關工作,讓我們剛進中心實習時不會不知道要做甚麼,平時除了工作上的交流,也會分享一些彼此生活上的趣事,讓實習工作不會這麼嚴肅。

實習期間完成之進度
研究動機
肺部在人體中扮演著重要的角色,然而,肺癌和肺炎等疾病造成了許多人的死亡。為了預防這些疾病,我們通過胸部X光攝影(CR圖)和電腦斷層掃描(CT圖)來檢測這些疾病。CT圖像是一種醫學影像技術,通常用於獲取人體內部的詳細橫截面圖像,CT圖讓我們能夠觀察身體內部組織和結構的細節,包括頭部,胸部等器官,都適合用此技術來讓醫師進行診斷。醫學影像在臨床醫學中扮演著關鍵角色,用於疾病診斷和預測。然而,大量的醫學影像數據帶來了挑戰,僅依賴手動觀察和主觀判斷可能會給醫護人員帶來負擔。
近年來,使用深度學習進行醫學影像識別以預測疾病已經成為一個普遍的趨勢。此外,深度學習不僅能夠區分惡性和良性的肺部結節,還能生成增強的肺部結節圖像,提供更豐富的視覺信息。在這個專題中,我們將訓練多種模型(ConvLstm2D、ConvLstm3D、GAN)來生成肺部結節影像。
研究方法
我們使用CNN(Convolutional Neural Network)這個模型,然後結合長短期記憶(Long Short-Term Memory,LSTM),進而處理具有時空關係的影像,最後再利用ConvLstm3D處理三維(立體)數據,然後生成對抗網絡(GAN)是生成圖像使用的。
為什麼使用ConvLstm作為模型?
1. 時間序列特性: ConvLstm專為處理時間序列數據而設計。在時間序列的肺結節影像中,可能存在隨著時間變化的模式,而 ConvLstm 可以有效地捕捉這些時間序列特徵。
2. 空間特徵: 肺結節影像不僅具有時間序列特性,還包含了空間資訊。ConvLstm 在卷積層中引入了LSTM單元,同時考慮了時間和空間特徵,有助於更全面地理解和預測影像序列。
3. 減輕人工負擔: ConvLstm模型的端對端學習使得模型能夠自動從數據中學習特徵表示,無需手動提取特徵。
為什麼使用GAN作為模型?
1. 數據擴增:GAN可以生成與現有數據相似但不同的合成數據,可以擴展數據集。
2. 生成未來趨勢: 對於時間序列的數據集,使用 GAN 可以生成未來時間點的影像,有助於預測未來影像的趨勢。
研究過程
資料集介紹:Luna16資料集
Luna16資料集是2016年為了大規模評估肺結節檢測演算法而推出的肺結節檢測資料集,其資料來自LIDC-IDRI。為了使CT資料更加標準,LUNA16增強了LIDC-IDRI中切片厚度更大3 mm、切片間隔不一致以及部分切片夾緊的CT,最後產生888張CT,保存為.mhd格式。在這888張CT中,共有36,378個來自LIDC-IDRI的標籤。LUNA16也提供了用於進行快速剔除的候選區域標記,候選區域的計算方式採用現有的剔除候選檢測演算法。由於病灶可以被多個候選者檢測到,因此將中心位置小於5毫米的候選區域合併。使用此方法,在1186個結節中,有1120個結節被檢測出551,065個候選區域,其中每個個區域候選都被標註了類別標籤,0代表非結節,1代表結節。
深度學習模型介紹:
(1)ConvLstm2D:
ConvLstm2D是一種神經網絡架構,結合了卷積神經網絡(Convolutional Neural Network,CNN)和長短期記憶(Long Short-Term Memory,LSTM)。它在處理具有時空關係的數據時表現出色,能夠同時處理空間信息和時間序列信息。卷積神經網絡(CNN)主要用於處理圖像數據,能夠提取出圖像中的特徵。而長短期記憶(LSTM)是一種遞迴神經網路,用於處理序列數據,能夠捕捉到序列中的長期依賴關係。ConvLstm2D結合了CNN和LSTM的優點,能夠處理具有空間結構和時間序列關係的數據。它使用卷積操作來處理空間訊息,並使用LSTM單元來處理時間序列訊息。在每個時間步(Time step)上,ConvLstm通過卷積操作在空間維度上處理輸入,並通過LSTM單元在時間維度上處理序列。
(2)ConvLstm3D:
3D Convolutional Neural Network,是一種深度學習模型,特別用於處理三維(立體)數據,例如視頻和醫學影像。與傳統的2D CNN(卷積神經網絡)不同,3D CNN 考慮了時間維度,因此適用於需要對立體數據進行空間和時間建模的應用。
以下是3D CNN的一些基本概念和特點:
三維卷積層(3D Convolutional Layers): 3D CNN 使用三維卷積層來處理立體數據。這些卷積層包含三個維度的卷積核,可以捕捉立體空間中的特徵。這使得模型能夠理解立體數據中的空間和時間相依關係。
3D池化層(3D Pooling Layers): 與2D CNN 中的池化層類似,3D CNN 使用3D池化層來減小特徵圖的大小,同時保留重要的空間和時間信息。3D池化通常使用立方體(3D cubes)來進行操作。
時間卷積(Temporal Convolution): 3D CNN 的一個關鍵特點是它能夠處理時間序列數據。這通常通過在卷積操作中引入對時間維度的卷積來實現,以捕捉數據中的時間相依性。
應用領域: 3D CNN在許多領域都得到了廣泛應用,特別是在視頻分類、動作識別、醫學影像分析等方面。在這些應用中,模型需要理解立體數據中的動態變化,而3D CNN正是為此而設計的。
計算複雜度: 由於3D CNN需要處理三個維度的數據,因此計算複雜度較高,需要更多的計算資源。這也是在實踐中需要較大計算能力的原因之一。
在實作過程中,64個LSTM units依照4 ∗4 ∗4的方式排列,經過下圖所示的計算之後,取每個unit的Nh維的hidden state作為輸出。也就是之前所說的4 ∗4 ∗4的voxels(4D-tensors)
計算符號的涵義如下:
上述等式左邊的符號意義分別為forget gate、input gate、memory cell、hidden state。與標準的LSTM不同的是,僅在最後的時候使用output gate,減少了參數數量。
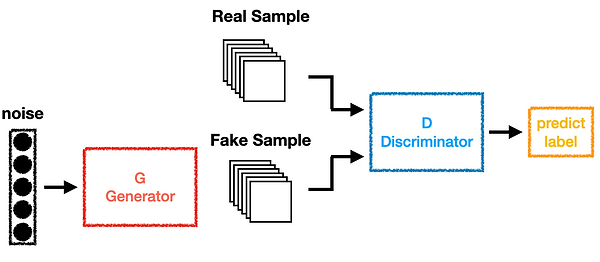
(3)Generative Adversarial Network:
生成對抗網絡(GAN)是一種常用於生成圖像、音樂、影片等資料型態的深度學習模型。它由兩個關鍵組件組成:生成器和判別器。
生成器的任務是生成與真實數據相似的資料,而判別器的任務是區分生成的資料與真實數據。當判別器讀到一筆資料後,他需要對資料進行評分或是提供是真實資料的機率。
生成器和判別器就像是兩個競爭對手,總是在相互競爭中。通過這種對抗過程,兩個網絡不斷改進自己的能力,直到生成器生成的合成數據難以區分為真實數據。總結來說,這是生成對抗網絡的演算法:
1. 初始化生成器和判別器
2. 固定生成器G,訓練判別器D
3. 固定判別器D,訓練生成器G
4. 重複步驟2和步驟3







模型訓練結果
我們丟入第一幀影像和第二幀影像讓ConvLSTM2D模型訓練並且預測出第三幀,並將其與原始第三年使用SSIM進行預測準確率比較。
SSIM介紹:
SSIM(結構相似性)是一種衡量圖像相似性的指標,用於比較兩個圖像之間的結構差似度,百分比越大越好。此指標主要是比較兩張圖相似程度,由-1表示不相似到1表示完全相同。因此也常用來評價除噪(De-noising)或除雨(De-raining)的模型或方法,可以比較圖片、影像除噪或除雨前後的效果。將處理過後的圖與目標圖(Ground Truth)計算SSIM,若越接近1表示處理的越接近我們要的結果。
SSIM主要為比較兩張圖的三個指標,亮度、對比度和結構:
亮度 (Luminance)
對比度 (Contrast)
結構 (Structure)
最後將三個指標相乘即可得到SSIM。
SSIM = Luminance * Contrast * Structure
使用convLstm2D模型的結果分成三類:
1.(只使用肺結節會變小的數據集讓模型訓練)
驗證數據集的平均準確率 (SSIM):0.5599(越大越好)
2.(只使用肺結節會變大數據集讓模型訓練)
驗證數據集的平均準確率 (SSIM):0.5999(越大越好)
3.(使用混合數據集(變大+變小)讓模型訓練)
驗證數據集的平均準確率 (SSIM):0.7110(越大越好)
使用convLstm3D模型(3D混合數據集)的結果:
驗證數據集的平均準確率 (SSIM):0.0003(越大越好)
使用GAN模型的結果分成二類:
1.(使用2D混合數據進行訓練)
驗證數據集的平均準確率 (SSIM):0.2821(越大越好)
2.(使用3D混合數據進行訓練)
驗證數據集的平均準確率 (SSIM):0.2894(越大越好)



.png)
總結
1. 在ConvLstm2D模型方面,混合數據集的表現優於單一方向的變化,顯示出模型對於多樣性數據的適應能力。
2. ConvLstm3D模型的結果顯示其性能極低,而GAN模型在2D和3D數據訓練下表現相當,但準確率相對較低,可能需要進一步優化或考慮其他模型結構。
3. 整體來說,ConvLstm2D在處理多樣性數據上表現較好,而GAN的效果相對較差,可能需要進行進一步的調整和優化。 ConvLstm3D的結果顯示需要更深入的調查和改進。